· 12 min read
Visualizing Dynamic Behavior Flow

Editor’s note: This post was written in collaboration with Shawna Baskins and Joseph Riley. We’d like to extend a special thanks to Peter Landwehr for making the behavioral data from Glitch available.
Introduction
One of the most important challenges in game analytics is to take the power of quantitative analysis and place it into the hands of everyone, not just trained analysts. In this post we describe the process of developing a method for generating behavioral profiles and visualizing how players over time migrate between these profiles. As a case example, we’ll use the auction house behavior in the late but very endearing, browser-based MMORPG Glitch. Finally, we discuss why such visualizations can be a good addition to your web-based dashboard.
Games can generate massive amounts of behavioral telemetry data, which can be time-dependent and often high-dimensional. For example, records of a player across months of play, with dozens of different types of actions, events and similar tracked. One problem is analyzing the data, another is making them, and the results of the analysis, accessible to the stakeholders that need to decide what actions to take based on the information obtained.
The field of data visualization has grown up in the past 2-3 decades to deal with the challenge of communicating data and analysis results. In games, given the often complex nature of the data we deal with, visualization is a particular challenge.
Another challenge that is common across all games is behavioral profiling. We want to understand players, and while behavioral telemetry, sales records, virality data etc. provide excellent raw material to work with, generating and validating behavioral profiles that accurately model groups of players, requires some knowledge of data mining. Moreover, there is the issue of players having a tendency to change their behavior over time, so profiles have to be dynamic.
In this post we try to tackle both these challenges, focusing on in-game behavioral telemetry (gameplay telemetry) and one specific machine learning approach: clustering. What we present will not work in every situation, nor is clustering the only way to build profiles, but it will serve as an example of the usefulness of generating behavioral profiles, and visualizing their dynamics as a function of time (or so we hope).
The case we will adopt as an example is Glitch. The game, developed by Tiny Speck, was an endearing browser-based MMORPG that lived for about 14 months, during which time attracted more than 20,000 players. Our specific focus here is the trading behavior of these players, who generated about 3 million auctions across more than 650 items over the lifetime of the game, and that had a success rate of 85%.

Glitch operated with an in-game soft currency – Currants. Players could obtain the currency by questing, grinding/harvesting, or selling items to other players. Similar to other MMOs, players could post any quantity of an item in an auction house. Postings expired after 3 days, and Tiny Speck would claim a small fee for each of the items.
Grouping players
A great way to begin understanding your player population is through segmentation, fundamentally the process of divvying up the population into groups that share one or more characteristics, for example age, geographic location, monetization pattern, churn ratio and so forth. Studying segments more closely leads to more well-defined insights on the different groups of players; and they can also be used for evaluating engagement, A/B-testing, soft launching, etc. This is why any tool for game analytics worth its’ salt includes some sort of functionality for segmentation (including cohort analysis and funnel analysis).
In unsupervised data mining – the kind of data mining where we do not make assumptions about any underlying structures in the data we are looking at (this is generalizing, and it is important to note that we do make assumptions of the data themselves), but operate in a more explorative fashion – one of the most common approaches to finding patterns in datasets is cluster analysis.
Cluster analysis, or just clustering, is the process of grouping a set of objects (here typically players) in such a way that objects within any one group (called a cluster) are more similar in some sense or another to each other, than to any object in another cluster. The specific way group membership and similarity is calculated varies immensely from model to model.
Of the multitude of techniques for cluster analysis, perhaps the most common is called k-means clustering. With this particular technique, the idea is to group together players that have strong similarity within the group, and strong dissimilarity from other groups. New observations are classified by the shortest distance to a group’s center, which can be based on any dimension of your choosing (money spent, time played, days played, in-game friends, level completion ratio …). While there are some defined rules for accomplishing this task, there is an art in defining what players will be segmented on, how many player groups we should try to create, and what segments should be called (in fact, naming clusters can be incredibly important to interpretation).
We used k-means clustering (for a more in-depth description of the methodology see here) and an array of metrics related to the auction house (economics KPIs such as completed auction, total auctions posted, etc.) to segment players based on how they use and engage with the auction house in Glitch, across 14 monthly time bins. We also included information about whether the player had been active in the economics forums of the game.
Identifying Player Personas
This segmentation resulted in 4 higher level player clusters occurring each month, with a few additional sub-segments based on particular indicators occurring less frequently.
1. Hardcore
High activity with the auction system with good sales success. These players perform at the upper bound of all KPIs
2. Forum
A smaller group defined by hardcore profiles but also additional engagement with community forums.
3. Moderate
Characterized by moderate values in the KPIs. Comes in three flavors: Farmers post a large number of auctions per day across a smaller range of item categories. These players are focused and establishing a trade niche within the economy. Miscellanea are less focused, instead posting auctions across a broader range of categories at a more leisurely pace (i.e. fewer auctions per day). Losers post more frequently than Miscellanea but are less successful than all other clusters in the moderate category.
4. Casual
Characterized by low to very low activity, and generally low values in the different KPIs. Generally comprised of two distinct groups: those that make money off their auctions, few as they are, and those who don’t. The latter is particularly prone to churn.
Visualizing Flows
One of the challenging (and fun) aspects of working with behavioral data is their temporal nature. Players rarely exhibit constant behavior over time. While we can make generalizations about player behavior types, what if we wanted to see how these behaviors change over time? Do players from one segment tend to flow into another segment in the next period (or churn)?
To visualize flows, we looked to Sankey diagrams, which are historically used in physical science fields to visualize transference between energy states or in the manufacturing industry to explain process flows. Of course, this article would be remiss without including the most famous of all sankey diagrams, frequently used in data via textbooks: Charles Minard’s diagram of Napolean’s invasion of Russia, showing the declining amount of troops on the march to and from Russia. We felt that a modified version of this would be a great foundation for a tool to explore player migration between different behavioral profiles over time.

D3 and Interactive Visualization
For implementation, we utilized Mike Bostock’s D3 javascript library. D3, Data Driven Documents (http:/d3js.org/), centers on the idea of binding HTML elements or SVG shapes to data. This is referred to as a DOM manipulation framework, much like the popular jQuery, and it is entirely open-source. Others have built off Bostocks work, providing wrappers for D3 code to create reusable functions for graph types (D3 Plug-ins, NVD3, xCharts) or higher-level languages to quickly build basic chart types (Vega.js). There are even R and Python connections, rCharts and Vincent respectively, that can get you experimenting with D3 very easily if you are more accustomed to those languages for your analysis. Additionally, as this is open source, there are plenty of online tutorials and books to get you started in using D3.
The sankey diagram is a D3 plugin, and the benefit will be that it won’t require any custom code to replicate the style of the sankey demo and it should not require too much custom code to replicate our take. To get a feel of what this technique is actually providing, take a look at that demo page (diagram example also shown below).
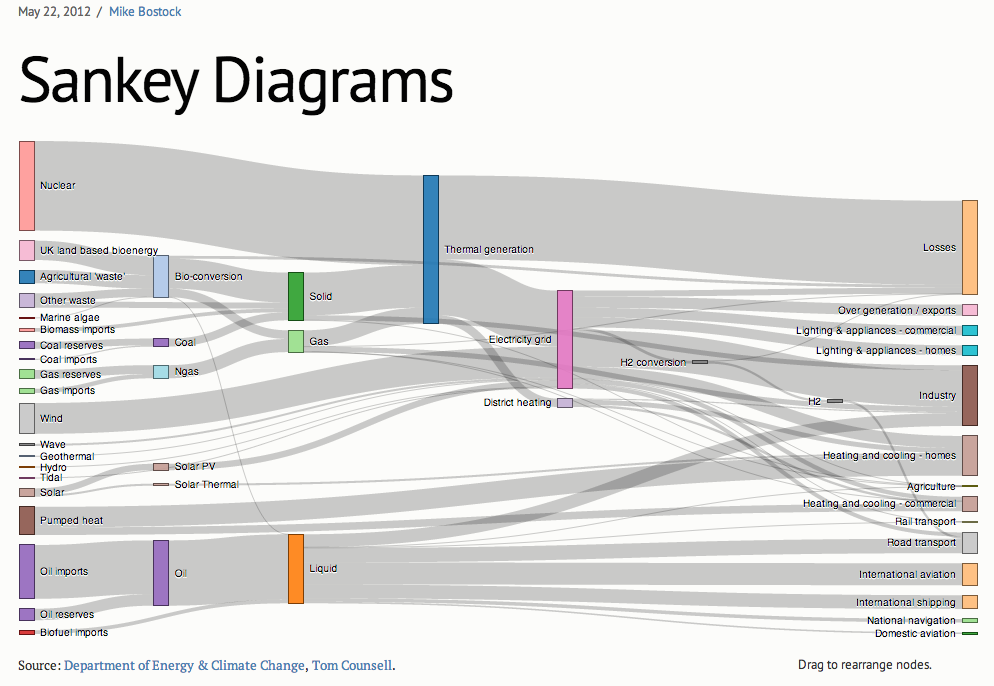
The example diagram shows connections between energy demands on the right, raw inputs on the left, and means of generation in the middle. Links are sized relative the amount of influence on the receiving node. Click and drag functionality is built into the demo, allowing viewers to drag nodes around the screen.
How can we visualize behavioral shifts?
We want to make the leap from energy generation to player migration between segments over time. While the sankey diagram is visually rich, we needed to make this a fully functional dashboard tool replete with drill down click capabilities and raw values, and player departure information. Incorporating elements of a stacked bar chart allowed us to enrich the dashboard for a wider audience. Here’s a link to the final product and a screenshot.
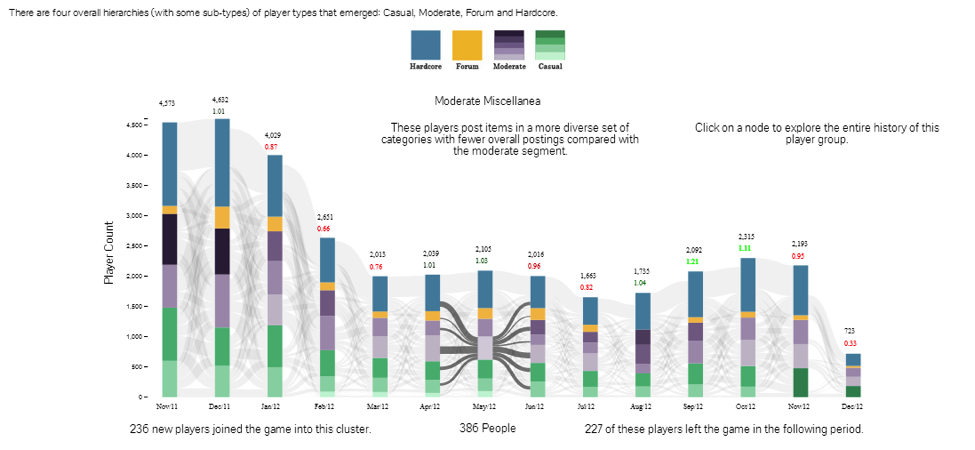
Furthermore, we also wanted to know what happened to a particular group of users during the entire lifetime of the game. For the drill down application we incorporated separate cases for mouse-over and click-through. We employed a mouse-over function that shows where these players existed in previous and future months. Clicking on a bar segment will also filter the entire data set for that specific month and cluster in a bar chart.
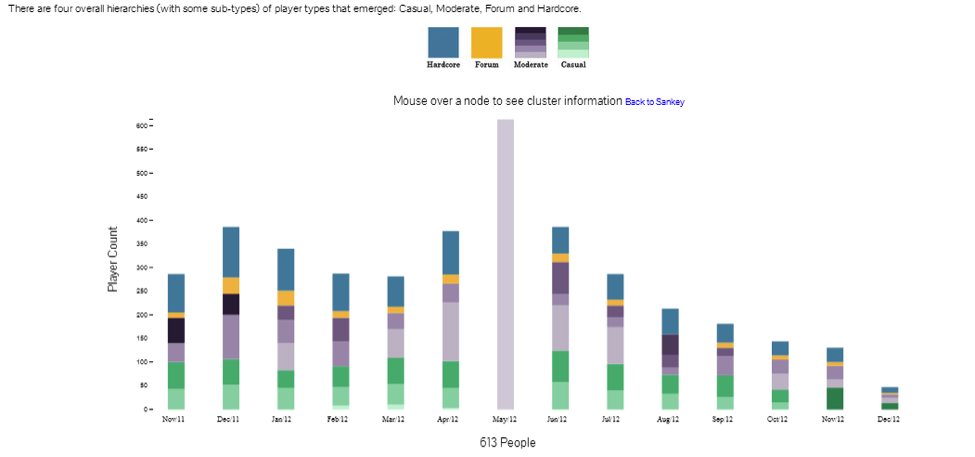
Through this we can better understand the distribution of players that lead up to the select pointed, including new players. Though more complicated, there is nothing stopping the ability to map the sankey flow links into this drilldown view as well.
Creation stacked bars
The following section will go through a bit of the code base, with the source found here. While D3 can handle data in any format, Sankey.js is looking to parse a JSON file (a hierarchical data format) containing information on nodes

and links.

While the sankey diagram will require some understanding of d3.js, creating the figure is simply a matter of calling a function and specifying a few parameters.

We play with a few of these inputs to create the stacked bar chart format. In particular, we reduce the nodePadding to zero (the amount of whitespace between nodes vertically), changing the layout to 1 (this deals with iterations of the positioning algorithm to find the best placement, and for us reducing this to one pass drew bars from the top of the canvas downward), and then we utilize the SVG transform attribute to essentially flip the screen, so that nodes are drawn from the bottom upwards. Most importantly, we structured our JSON file such that the order of the segments is the same (for the segments that exist at each interval).
Visualizing dynamic player behavior
We can expand the idea of this type of data exploration to different dimensions very easily. It could be rather powerful to view player trends over level or XP progression, events or funnel analysis.
The framework can also be used to look at user revenue over time for microtransactions in mobile games. Typical measures such as ARPU and ARPPU are reported aggregately in discretized time period, without looking at how individual user spend varies over time. For example, do users make all their purchases upon joining the game, or do they exhibit continuous and consistent spend levels as they progress in the game? Moreover, the group mechanics do not have to be the result of segmentation and could just represents bins of player spend, transaction counts, game events completed, marketing channel, etc. Another case use for this tool would be to track players at risk of leaving the game by simply adding another bucket for new players and another bucket for departing players. The Glitch visualization shows this information as text at the bottom of the chart; however, it would be simple to incorporate this into the visual as well if the business objective demands it. Overall, sankey diagrams appear to have broad applications in the game analytics space and can be modified to show a variety of key performance metrics to stakeholders. For some follow-up work going into more detail with behavioral profiling and progression analysis, see here.
Overall, while the effort required to get this type of visualization up and running is more than an out of the box visualization tool, this can allow for a more customizable and interactive visual solution for monitoring your player base. The visual is admittedly dense with information. In this case by design, e.g. using fewer clusters or time bins makes for a less dense diagram. However, the sankey diagram is effective for organizing complexity and multiple dimensions and visualizing a lot of information in a small screen space. The sankey plug-in also provides for a less intimidating entry to getting a visual up and running with minimal custom code.
We hope this post has sparked some ideas on visualizing flows and ideas for a quick roadmap for implementation.