

Smarter mobile games start here
From real-time analytics to advertising insights and out-of-the-box data pipelines, we support mobile devs with tools to launch smarter, monetize better, and move faster.
Move from data to decisions with the IQ Suite. Built for modern studios to understand players, personalize experiences, and drive growth.
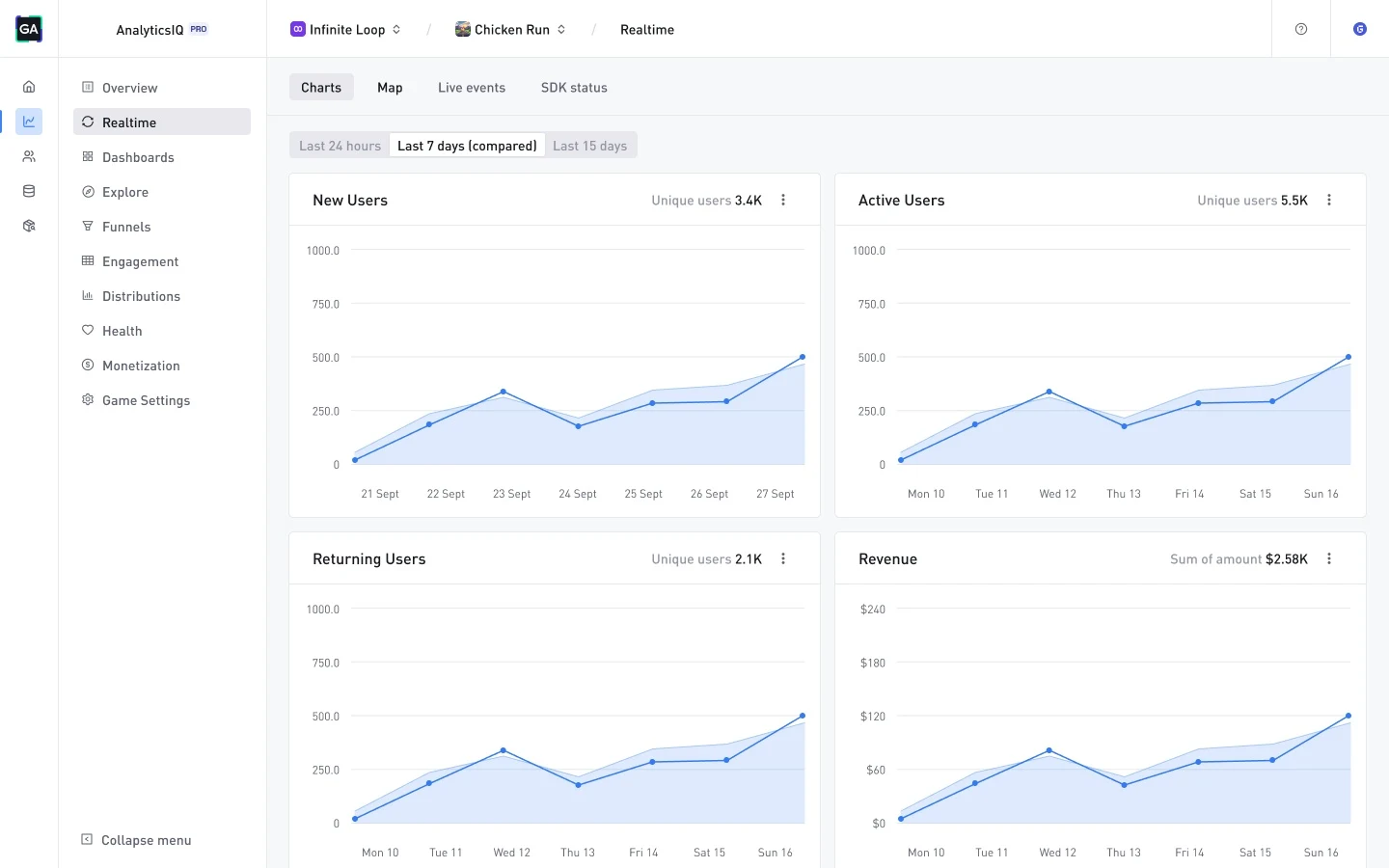
Turn data into insights with real-time analytics
Learn more
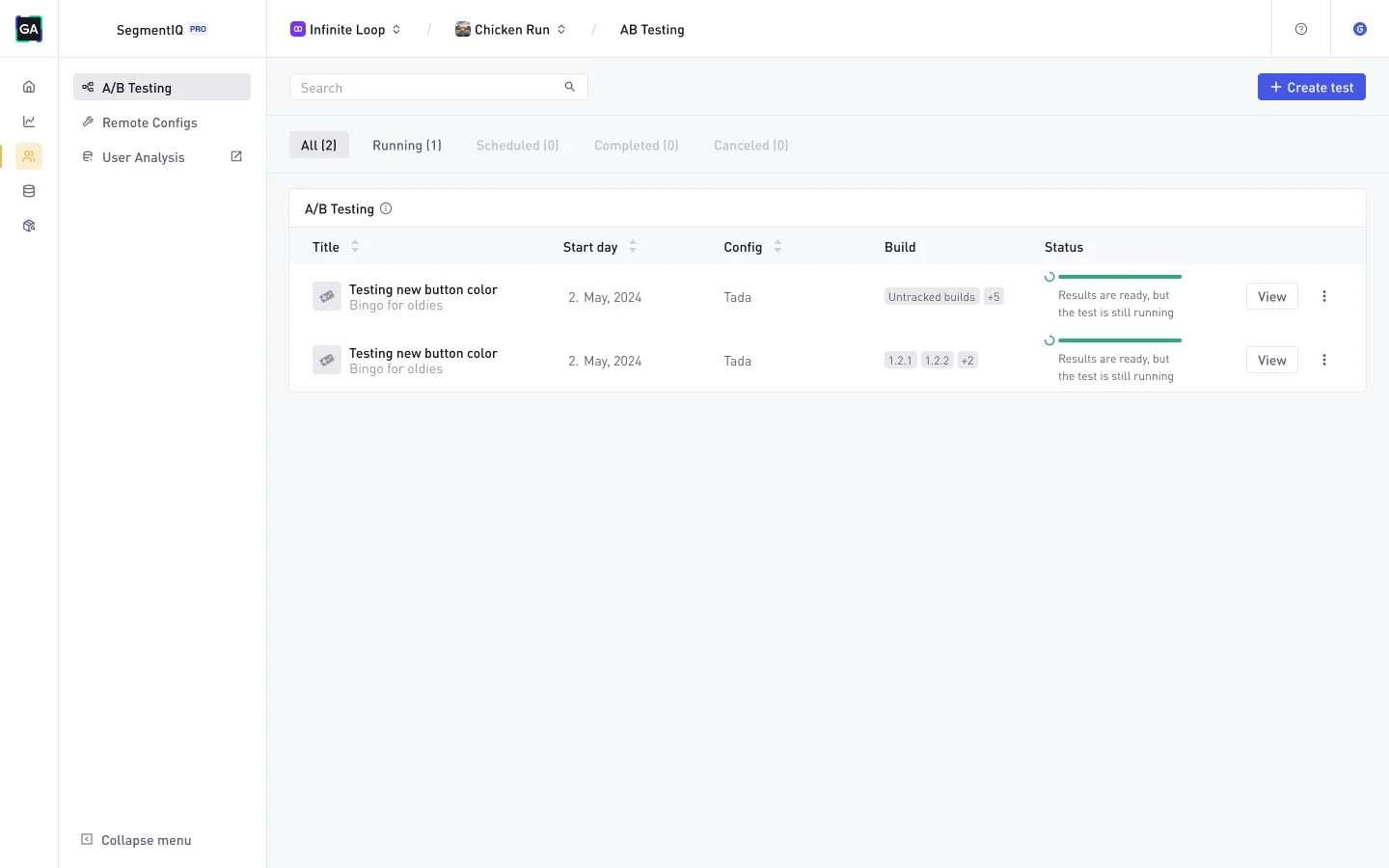
Understand and take action on your player segments
Learn more
Perform advanced analyses with prebuilt data pipelines
Learn more
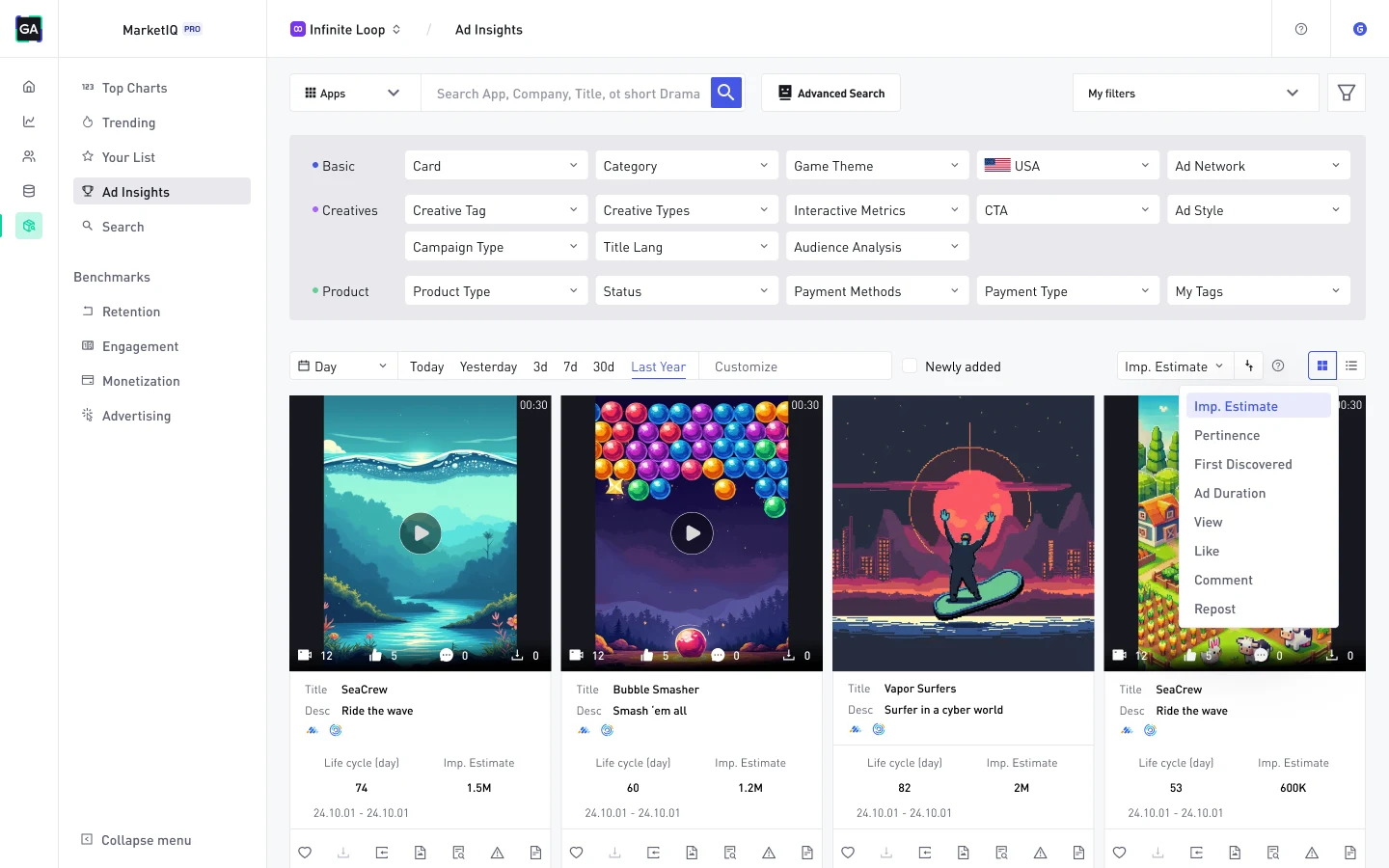
Access in-depth advertising and app intelligence
Learn more
ISO 27001
SOC 2
KidSAFE+
ePrivacy




















Increase
in ARPDAU
Higher
Day 1 retention
More interstitial
video impressions
Boost in monetization performance

Track acquisition, engagement and monetization in real time - and make smarter updates with instant insights.
AnalyticsIQ has been an essential tool for understanding real player behavior.


Create segments, run targeted LiveOps campaigns, and boost monetization with tools designed for precision and scale.
SegmentIQ is very useful. We tested and identified a winning ad strategy that increased APRDAU by 55%.


Access raw data, manage infrastructure, and give your engineers the freedom to build, scale, and analyze without limits.
I've been thoroughly impressed with the capabilities of PipelineIQ. It’s been instrumental in driving our growth.


Benchmark your games, monitor app trends, and find the creative campaigns driving real results.
I wouldn’t be able to do my job without MarketIQ and its creative performance data.

Power growth across every platform with tools built to scale alongside your studio.
From real-time analytics to advertising insights and out-of-the-box data pipelines, we support mobile devs with tools to launch smarter, monetize better, and move faster.

Gain actionable insights into both game performance and brand collaborations. Optimize player engagement, track monetization, and provide data-driven results for your brand partners.

Unlock deep insights into player behavior, optimize immersive experiences, and track performance across virtual and augmented worlds to elevate your games and drive engagement.

Unlock insights into player behavior, revenue, and engagement. From balancing gameplay to scaling monetization, our tools help studios grow successful titles across Steam, Epic and more.

From indies to global publishers, GameAnalytics powers the tools behind the world’s most successful games.
Connect with any of the major attribution, advertising and monetization services for deeper insights in minutes.










Trusted worldwide by game makers
studios powered by GameAnalytics
supporting the gaming industry
users making smarter decisions



Janzen Madsen
Founder
,
Splitting Point Studios
Maxime Besson
Growth Creative Strategist
,
Voodoo

Joe Ferencz
CEO
,
Gamefam


Alireza Khorshidi
Product Manager
,
Baloot Games


Saurabh Saxena
Lead Developer
,
GRX Immersive Labs







