· 5 min read
About Druid: Our New Backend Technology

By now, many of you will be aware of the fact that GameAnalytics is about to undergo a major technical overhaul. For the past 18 months, myself and a small team of engineers have been rebuilding (and also migrating), our existing infrastructure to an innovative new solution. That solution is called Druid, and it’s essentially a high performance data store.
In this post, my aim is to give more of a technical overview of the new systems and solutions that we’re putting in place. I hope this helps to give all users of our service more context about the change, why it was necessary, and the benefits it will bring. For more information about the upcoming changes, you can check out this Beta announcement post.
What is Druid?
Druid is an open source data store designed for real-time exploratory analytics on large data sets. The system combines a column-oriented storage layout, a distributed, shared-nothing architecture, and an advanced indexing structure to allow for the arbitrary exploration of billion-row tables with sub-second latencies. For a more detailed explanation into the architecture of this technology, take a look at this Druid whitepaper.
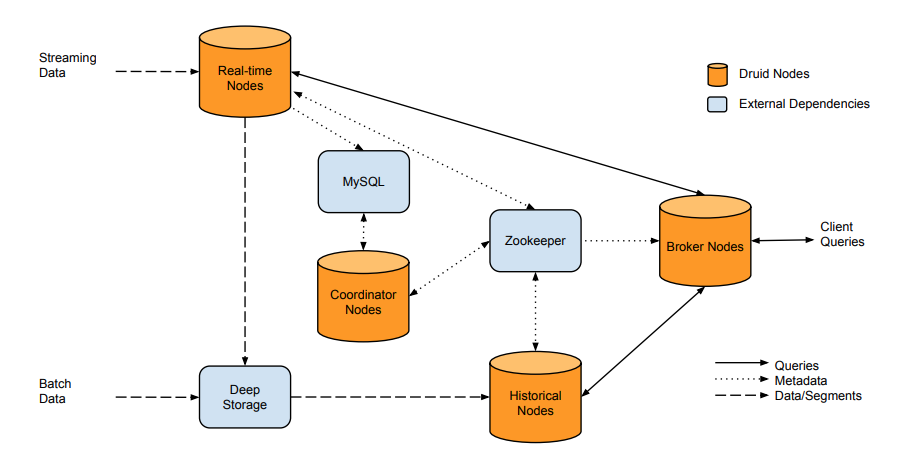
In its essence, Druid is a highly stable, innovative new solution for the storage and real-time querying of massive amounts of data. The technology was built to improve the scope of services provided by data collection and analysis companies – just like GameAnalytics.
Historical technology and challenges
I think at this point it’s worth sharing some key GameAnalytics stats.
On average, GameAnalytics collects and processes more than 600GB of data a day, for more than 2 billion devices intermittently sending small packets of data from every country in the world. We have more than 50,000 developers using the platform, and see 600M MAU in a typical month.
- Over 15,000 active games currently using our platform
- More than 15TB of data collected per month
- Up to 10M events per minute (yes, minute!) collected
Currently our technical infrastructure is managed with a backend programming language called Erlang. It was originally designed by Ericsson, who used to build massively scalable real-time systems with requirements on high availability.
The historical backend is actually pretty cool, it’s just not as flexible as we need it to be going forward; it needs to pre-calculate everything, making the addition of powerful new game analytics features more complicated. In addition, with the increasing amount of data outlined above, it became clear that the existing processing backend wouldn’t be able to provide the flexibility and scalability required to meet these needs. So, the search for a new backend, storage and processing solution began.
A better solution: why we chose Druid
One of our main requirements when selecting this system was ensuring that it offered the most flexibility, speed and scalability for the lowest cost possible. One particular issue with the old system was its inability to filter across different dashboards using multiple criteria based filters. Another important requirement was to be able to run new (ad-hoc) queries or calculate new metrics.
Druid was built for products that require real-time data ingestion of a single, large data stream. With Druid it is entirely within the realm of possibility to achieve queries that run in less than a second across trillions of rows of data. The image below illustrates how Druid addresses and streamlines the action of massive data processing.
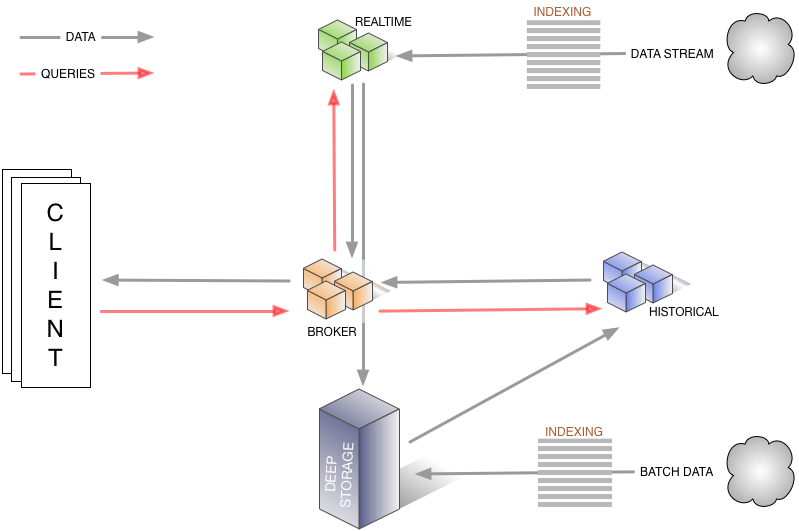
There is a good separation between the ingestion and the query side of the system: it’s not a big monolithic server. This makes for some very valuable benefits:
- It allows more fine-grained sizing of the cluster: we can scale it up or down in parts
- Errors in ingestion don’t propagate and users can still use our dashboards and other services, even if maintenance of the internal pipeline is necessary
- Flexibility in deploying redundant parts of the cluster:
- Deep store is kept safe
- Reprocessing data is relatively easy, without disturbing the rest of the DB
The new and old solution needed to be able to share as many components as possible, and the goal was to be able provide the same functionality and quality of service as before. Druid met this need, and more than surpassed all of our other requirements.
If you’re particularly interested in our exact implementation of Druid, I actually gave a talk about this back in 2017 at BigData Week in London. You watch the keynote below and access the slides here.
Final note
We are expecting to go live and migrate all GameAnalytics users into this new environment in July 2018. From that date you’ll notice some major changes in the tool for the better, but there may also be a period of instability whilst we streamline this new technology. Our engineers (myself included!) will be on hand during this transitional phase, so please don’t hesitate to get in touch via the friendly GameAnalytics support channel if you have any questions.